Best of the
Best
Editors' picks and our top buying guides











Best of the
Best
Editors' picks and our top buying guides
Latest

Tesla Recalls Cybertruck Due to Faulty Accelerator Pedal
4 minutes ago
Best Buy's Latest Weekend Sale Offers Tons of Tech and Home Deals, but There's a Catch
7 minutes ago
Taylor Swift and TikTok Are Going Steady Again as New Double Album Drops
17 minutes ago
Mortgage Market Brings Higher Costs to Borrowers: Mortgage Rates for April 19, 2024
18 minutes ago
Taylor Swift's New Album Is Here: Nabbing All the Bonus Tracks Will Cost You
24 minutes ago
Today Only: Save 50% on Our Favorite Home Security Cameras of 2024
29 minutes ago
Microsoft Visio Professional 2021 Is Down to $20 Off for Just a Few Days
32 minutes ago
'The Tortured Poets Department' is Out Today. What to Know About Taylor Swift's Double Album Shocker
33 minutes ago
You're Making Cheeseburgers Wrong. This Speedy Method Leaves Almost no Mess Behind
39 minutes ago
Walmart's $45 Million Settlement: How to Claim up to $500 in Settlement Cash
39 minutes ago
Best Vegan Meal Delivery Services for 2024
40 minutes ago
LED Face Masks Dazzle With Skin-Brightening Claims, but Do They Work?
40 minutes ago
22 Items in Your Kitchen You Should Toss Out Immediately
57 minutes ago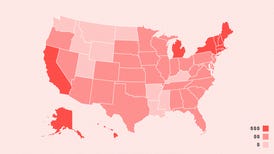
Compare Your Energy Choices and Electricity Rates by State
1 hour ago
Best Savings Rates Today -- Score up to 5.55% APY With One of These Savings Accounts, April 19, 2024
1 hour agoMore to Explore
Reviews, advice and more from CNET's experts.






Get the best price on everything CNET Shopping helps you get the best prices on your favorite products. Get promo codes and discounts with a single click.
Add to Chrome - it's free!
Our Expertise
Expertise Lindsey Turrentine is executive vice president for content and audience. She has helped shape digital media since digital media was born.
0357911176
02468104
024681024
Featured in
Tech














Upgrade your inbox
Get CNET Insider
From talking fridges to iPhones, our experts are here to help make the world a little less complicated.
Featured in
Money










Crossing the Broadband Divide
Millions of Americans lack access to high-speed internet. Here's how to fix that.







Featured in
Energy and Utilities












Deep Dives
Immerse yourself in our in-depth stories.



Get the best price on everything CNET Shopping helps you get the best prices on your favorite products. Get promo codes and discounts with a single click.
Add to Chrome - it's free!
Featured in
Internet








Sleep Through the Night
Get the best sleep of your life with our expert tips.







Get the best price on everything CNET Shopping helps you get the best prices on your favorite products. Get promo codes and discounts with a single click.
Add to Chrome - it's free!
Tech Tips
Get the most out of your phone with this expert advice.





Get the best price on everything CNET Shopping helps you get the best prices on your favorite products. Get promo codes and discounts with a single click.
Add to Chrome - it's free!

Featured in
Home










Living Off Grid
CNET's Eric Mack has lived off the grid for over three years. Here's what he learned.





